Про це розповідає KURAZH
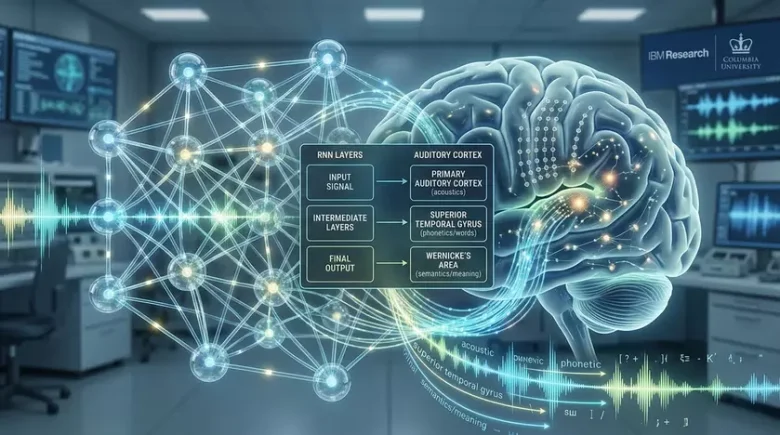
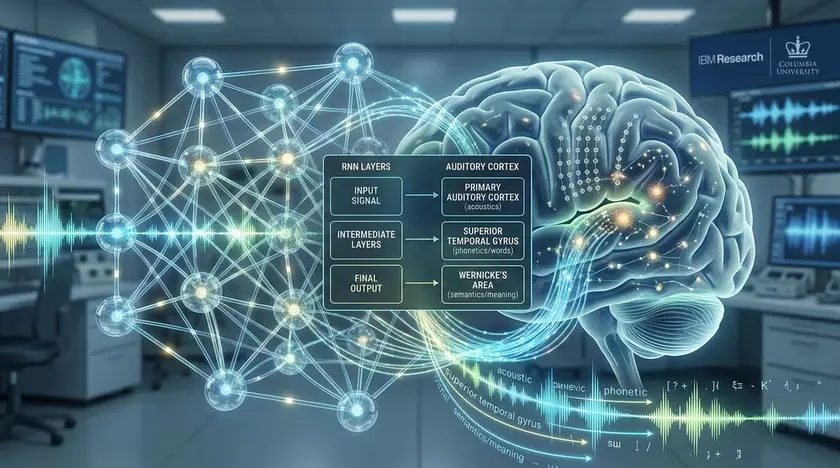
Вчені з Колумбійського університету та IBM Research встановили, що механізми обробки мови у людському мозку та штучному інтелекті мають вражаючу подібність. Дослідження показало, що як біологічна система, так і рекурентні нейромережі (RNN) проходять схожі етапи розпізнавання мовної інформації – від базових акустичних ознак до складних смислових конструкцій.
Унікальний експеримент на людському мозку
Для цього проекту науковці залучили 15 пацієнтів з епілепсією, яким вже було імплантовано електроди безпосередньо у слухову кору. Такий підхід дозволив фіксувати нейронну активність з високою точністю. Протягом експерименту пацієнти прослуховували розповіді, а дослідники записували реакцію їхнього мозку у реальному часі. Водночас ту ж аудіодоріжку подавали рекурентній нейромережі, навченій розпізнавати мову. Аналіз показав, що обидві системи проходять майже ідентичну ієрархічну послідовність обробки інформації: від виділення акустичних ознак і фонем до розпізнавання слів і складних смислових структур.
«Початкові шари штучного інтелекту корелювали з первинною слуховою зоною мозку, а більш глибокі — з ділянками, що відповідають за розуміння мови. Це підтверджує універсальність шляху від сприйняття звуків до формування ідей».
Мова, лінгвістика та нейромережі
Цікаво, що таку подібність можна спостерігати лише у випадку, якщо нейромережа навчалася саме тієї мови, яку аналізує людський мозок. Штучний інтелект, як і людина, структурує свої «знання» відповідно до мовного оточення. Якщо ж подати нейромережі, навченої англійської, наприклад, китайську мову, подібність у процесах обробки зникає. Це свідчить, що в основі лежить не лише математична схожість, а фундаментальний принцип опрацювання мовної інформації.
Автори підкреслили, що для дослідження навмисно обрали RNN, а не трансформери, оскільки мозок, на відміну від сучасних моделей ШІ, обробляє мовний потік послідовно. Саме поетапність RNN дозволяє проводити чіткі паралелі з біологічними процесами.
Отримані результати відкривають нові перспективи для використання штучного інтелекту як моделі людського мозку. Науковці зможуть тестувати різноманітні гіпотези про механізми мовлення без необхідності інвазивних втручань. Водночас ще залишається чимало запитань, зокрема, чому мовні функції у людини асиметричні і здебільшого локалізовані у лівій півкулі, чого штучний інтелект не демонструє. У подальших дослідженнях науковці планують з’ясувати, як мозок і алгоритми опановують другу мову та чи можливо завдяки цим моделям допомогти людям із мовленнєвими порушеннями.
Наразі, поки одні компанії фокусуються на вдосконаленні «розумової» здатності алгоритмів, інші, такі як Meta, співпрацюють із медіа для підвищення точності та людяності відповідей завдяки якісним даним.











