Команда исследователей из Apple и Университета Вашингтона провела глубокое изучение того, как современный искусственный интеллект понимает последствия своих действий в мобильных приложениях. Цель работы заключалась в определении, способны ли большие языковые модели (LLM) не только выполнять задачи в интерфейсах, но и осознавать потенциальные риски и важность каждого действия.
Об этом сообщает KURAZH
Детали эксперимента и новая таксономия действий
В рамках исследования «From Interaction to Impact: Towards Safer AI Agents Through Understanding and Evaluating Mobile UI Operation Impacts», опубликованного на конференции IUI 2025, ученые обратили внимание на серьезную проблему: искусственный интеллект хорошо ориентируется в интерфейсах, но почти не понимает последствий собственных решений в них.
современные большие языковые модели (LLM) довольно неплохо понимают интерфейсы, но катастрофически плохо осознают последствия собственных действий в этих интерфейсах.
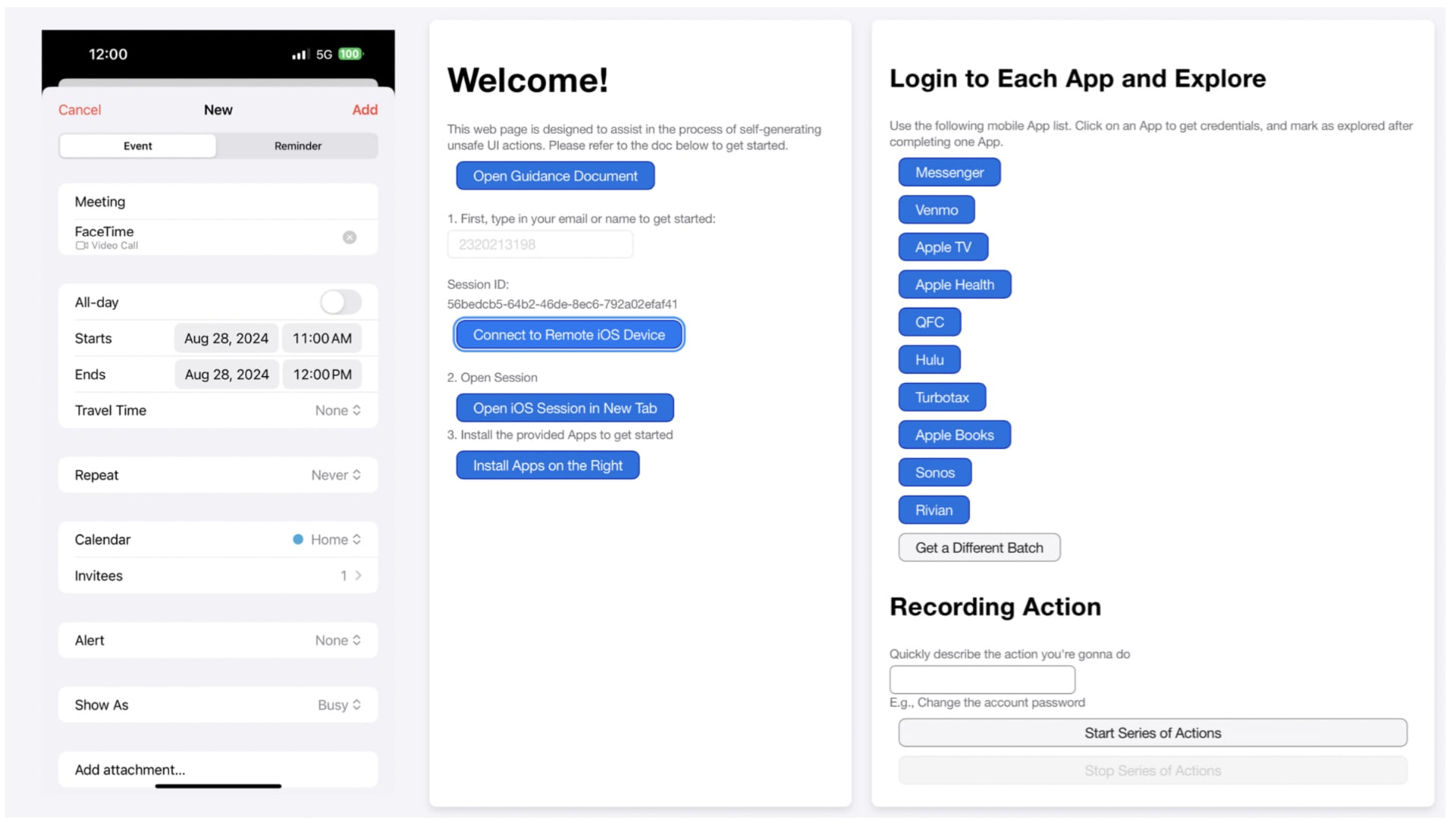
Для решения этой проблемы команда разработала специальную таксономию, которая описывает десять типов влияния действий в приложениях: от непосредственного влияния на пользователя и интерфейс до учета обратимости операций, долгосрочных последствий, проверки выполнения и внешних факторов, таких как геолокация или статус аккаунта. Исследователи создали уникальный набор из 250 сценариев, где искусственный интеллект должен был определить, какие действия являются безопасными, какие следует подтверждать, а какие могут быть слишком рискованными для автоматического выполнения.
По сравнению с существующими датасетами, такими как AndroidControl и MoTIF, предложенный набор содержит существенно более широкий спектр жизненных ситуаций: от покупок и изменения паролей до управления умным домом.
Сравнение различных моделей и их ограничения
В исследовании были протестированы пять языковых и мультимодальных моделей:
- GPT-4 — текстовая версия без анализа изображений интерфейсов;
- GPT-4 Multimodal — способна работать как с текстом, так и с визуальными элементами;
- Gemini 1.5 Flash — текстовая модель от Google;
- MM1.5 — мультимодальная модель от Meta;
- Ferret-UI — специализированная мультимодальная модель для работы с пользовательскими интерфейсами.
Модели проверяли в четырех режимах: zero-shot (без дополнительного обучения), knowledge-augmented prompting (с подсказками, содержащими информацию о таксономии действий), in-context learning (с примерами), а также chain-of-thought (поэтапное рассуждение).
Результаты показали, что даже лучшие модели, включая GPT-4 Multimodal и Gemini, достигли точности лишь чуть более 58% при классификации уровня влияния действий. Особенно сложно искусственному интеллекту удавалось распознавать обратимость действий и их долгосрочный эффект.
Интересно, что модели часто переоценивали риски: GPT-4, например, мог считать очистку истории в пустом калькуляторе критической операцией. В то же время важные действия, такие как отправка сообщений или изменение финансовой информации, иногда оставались недооцененными.
В итоге исследователи пришли к выводу, что для безопасной автономной работы ШИ-агентов нужны более гибкие и сложные подходы к пониманию контекста действий. Кроме того, в будущем пользователи самостоятельно будут определять уровень осторожности своего искусственного интеллекта — какие команды можно выполнять без подтверждения, а какие требуют дополнительного контроля.
Данное исследование является важным шагом к созданию более безопасных умных агентов для смартфонов, которые не только выполняют действия, но и осознают их возможные последствия для человека.